作者:Liang Wang and Nan Yang and Furu Wei Microsoft Research
来源:EMNLP
发表时间:2023年
一、背景
Information retrieval (IR) :
是现代搜索引擎中的核心组件,研究人员已经在这个领域投入了几十年。IR 有两种主流范例:基于词典的稀疏检索,如BM25,和基于嵌入的稠密检索。
Query expansion:
基于伪相关反馈或 WordNet 等外部知识源重写查询。对于稀疏检索,它可以帮助弥合查询和文档之间的词汇差距。大多数最先进的密集检索器都不采用这种技术。
Large Language Models (LLMs) :
仅需少量高质量示例的标注,即可实现最少的人工干预。在本文中,我们采用少量样本提示从给定查询中生成伪文档。
二、query2doc方法
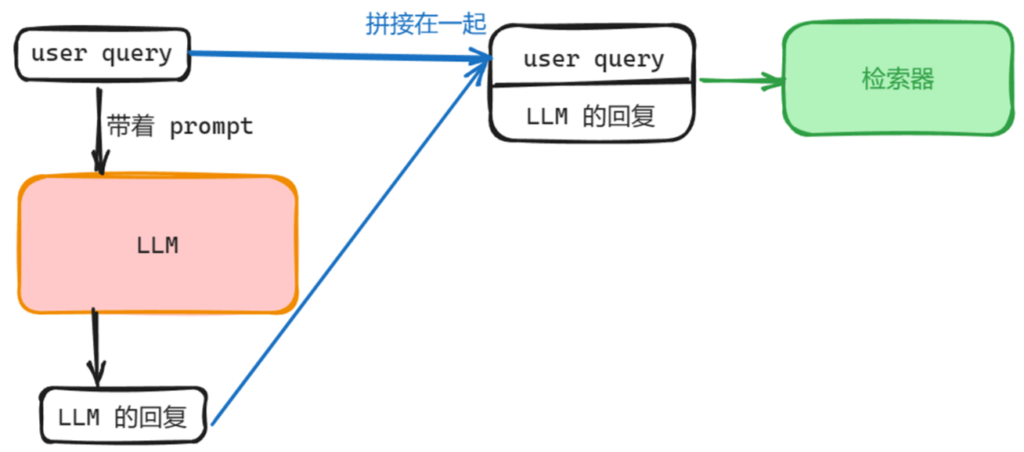

给定一个查询 q,使用少样本提示生成一个伪文档 d′,如图 所示。
提示包括一个简短的指令“写一段文字来回答给定的查询:”和从训练集中随机抽取的 k 个标记对。
本文始终使用 k = 4。
随后,将 q 重写为一个新的查询 q+,方法是与伪文档 d′ 连接。对于稀疏和密集检索器,连接操作不同。
◆稀疏检索:
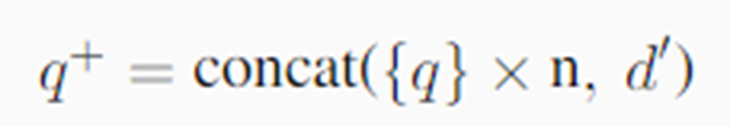
由于查询 q 通常比伪文档短得多,为了平衡查询和伪文档的相对权重,我们在将查询 n 与伪文档 d′: 连接之前,通过重复查询 n 次来提升查询词的权重
◆密集检索:
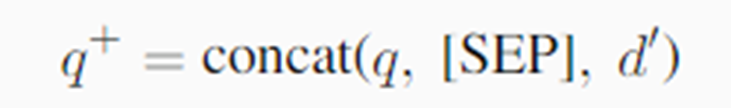
新查询 q+是原始查询 q和伪文档 d′的简单串联,用 [SEP] 分隔
◆训练密集检索器
设置一:训练从 BERTbase 初始化的 DPR 模型,仅使用 BM25 难样本。优化目标是标准的对比损失。
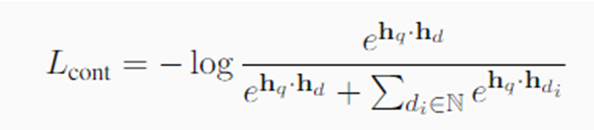
设置二:建立在最先进的密集检索器基础上,并使用 KL 散度从交叉编码器教师模型中蒸馏。
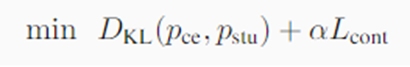
三、实验
(一)设置
◆域内评估:
使用 MS-MARCO 段落排序、TREC DL 2019和2020数据集。
◆零样本跨域评估:
从 BEIR 基准(Thakur 等人,2021)中选择了五个低资源数据集。
◆稀疏检索超参数设置:
包括 BM25 和 RM3,采用 Pyserini 中的默认实现。
◆训练密集检索器:
基本使用与 SimLM 相同的超参数,唯独将最大查询长度增加到 144 以包含伪文档。
◆提示大型语言模型时,包含 4 个上下文示例。
(二)结果
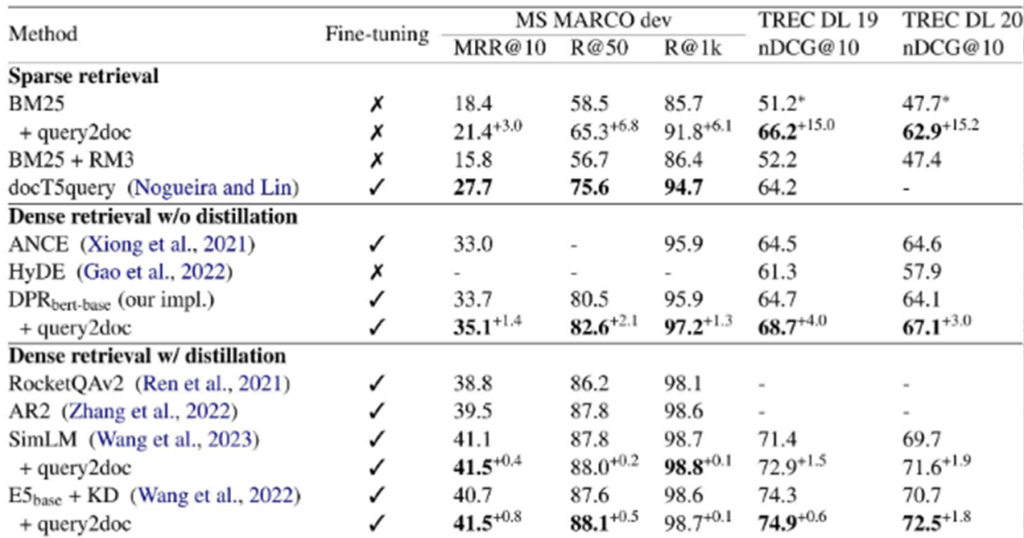
1.对于稀疏检索,“BM25 + query2doc” 在 TREC DL 2019 和 2020 数据集上比 BM25 基线 提高了 15% 以上。
2.对于密集检索,结合 query2doc 的模型变体在所有指标上都优于相应的基线。
四、分析
◆模型规模对查询扩展的质量的影响
◆从13亿模型到1750亿模型的过渡,性能稳步提高。 ◆可能原因:较小的语言模型生成的文本往往更短,并且包含更多的事实错误

◆将原始查询和伪文档连接起来作为新的查询
◆仅使用原始查询
◆仅使用伪文档
结果表明,原始查询和伪文档是互补的,它们的组合在稀疏检索中带来了显著的性能提升。

五、总结与综合对其思考
(1)总结
提出了一种名为 query2doc 的简单方法,利用大型语言模型 (LLMs) 进行查询扩展。
◆使用少量示例提示 LLMs 生成伪文档
◆通过将生成的伪文档添加到查询中,与现有的稀疏或密集检索器集成。
(2)综合对其思考
◆该方法的使用相比较与伪相关反馈这种查询改写方法,不依赖于初始检索结果的质量。
◆检索效果好但检索效率较低。
该方法需要使用LLM进行推理,逐个token的自回归解码,这可能会很慢。
使用query2doc,随着扩展后查询词数量的增加,搜索倒排索引也会变慢。