论文来源:ACM 2024.
作者单位:西安交通大学,中国科学技术大学,南方科技大学等
原文链接:https://doi.org/10.1145/3626772.3657722
一、背景介绍
微调医学领域的LLM通常涉及两个主要挑战:
1.任务多样性问题:
多任务学习框架最突出的是Mixture-of-Experts(MOE),它设计了多个独立的专家网络层来学习共享任务和特定知识,并集成了门函数来调节每个专家网络层的贡献。虽然现有框架巧妙地整合了经典神经网络架构的多个任务,但它们主要兼容与高调整成本相关的全微调。
2.参数高效微调:
现有的PEFT仅限于分别为每个任务微调多组参数或跨所有任务微调单个参数。虽然单独的训练可以很好地适应每个任务,但这种策略很费力,而且缺乏任务共享的知识。虽然微调一组参数是可行的,但由于数据不平衡,可能会损害模型性能。
二、主要内容
1、MOELoRA框架图
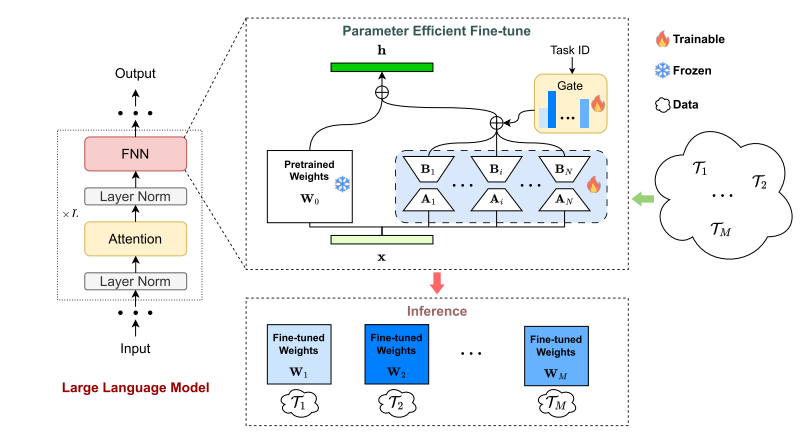
每个MOELoRA层都包含多个专家网络,旨在捕获各种医疗任务中的各种知识。随后,引入一个任务驱动的门函数,以确保为每个任务学习唯一的参数集。门函数确定所有MOELoRA层中专家网路的贡献权重,从而能够生成针对不同任务的特定更新参数。特别地,对所有MOELoRA层采用同一个门函数,而不是在门和MOELoRA层之间采用一一对应关系。对于微调过程,更新来自所有任务的混合数据的MOELoRA层。然后,MOELoRA可以在推理过程中为每个任务导出不同的微调权重。
2、MOELoRA的微调和推理过程

三、实验评估
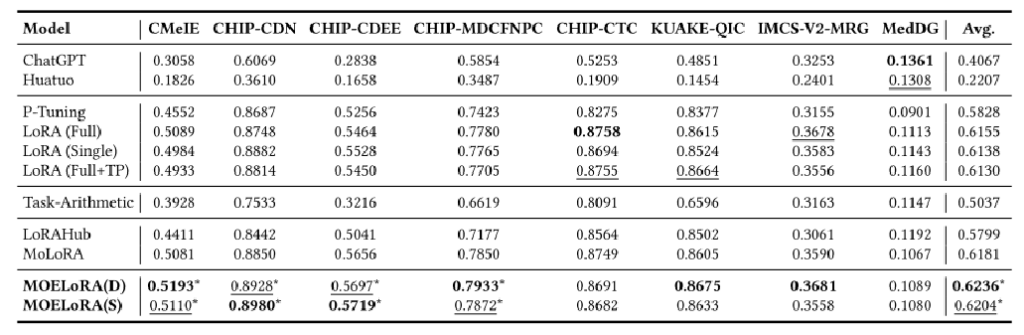
基线比较
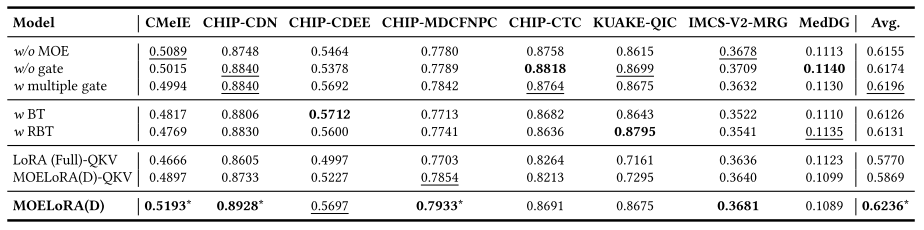
消融研究
四、论文总结
多任务学习能力:通过引入专家模块,MOELoRA能够有效处理多个任务之间的差异,避免数据不平衡对模型性能的负面影响。
高效的参数利用:LoRA的低秩矩阵设计显著减少了需要微调的参数量,使得模型在大规模参数下仍然能够高效地完成多任务微调。
任务特定的自适应能力:任务驱动的门控机制使模型能够根据任务动态调整专家的选择和权重,提升了针对不同任务的微调效果。
相比于全参数微调和传统的LoRA,MOELoRA能够在不显著增加计算成本的前提下提升模型性能。