2022 Institution of Chemical Engineers
本文研究如何在半结构化文本中识别因果关系,以及如何依靠小样本数据建立自动因果提取模型。结合专业领域,贡献集中在安全文本挖掘技术在LNG接收终端风险追溯和事故原因中的应用,具体包括以下三点:
1.提出HAZOP英文报告的结构化处理方法,使用标签标记显性和隐性因果关系,实现从复杂报告文本到因果关系文本的预处理。
2.在因果关系提取的深度学习模型中,提出了整合线性和图数据的特征训练方法,解决了小样本训练不足的问题。
3.自动提取风险追溯结果,实现专家经验的存储和人力的节约,为智能LNG接收终端的建设提供智能安全技术支持。
整体框架
首先,将风险因素文本输入LSTM网络,通过词向量学习获得线性特征。同时,语料库通过句法依赖形成邻接矩阵。这两个特征随后进行融合,以加强并执行注意力机制的权重分配。通过条件随机场(CRF)计算标签概率,并输出概率最高的标签,形成异常工作条件的因果节点。
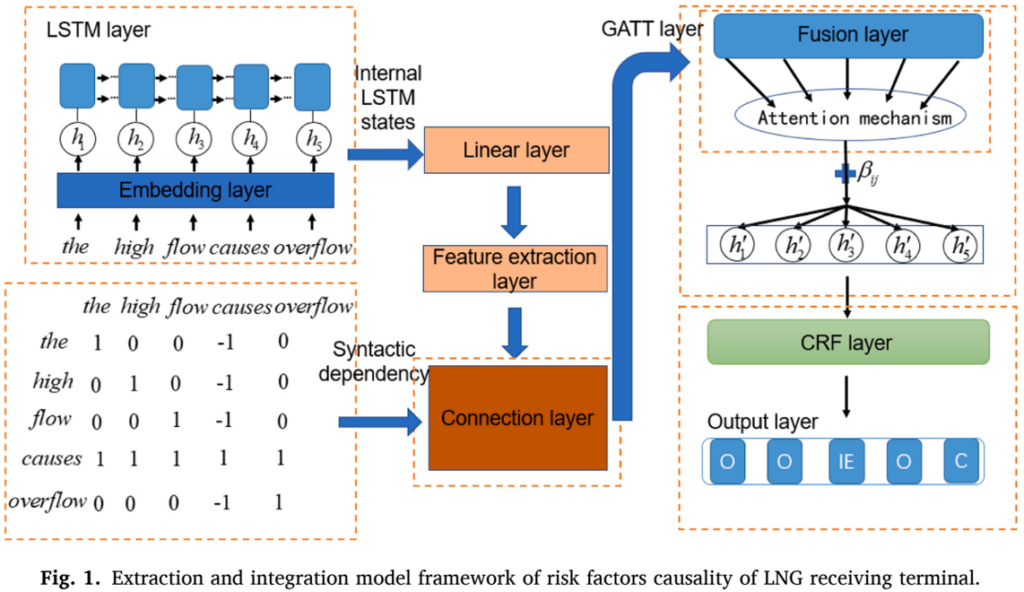
通过将文本构建句法依赖图,并将其用于图注意力网络的因果关系提取任务中。图注意力网络利用句法依赖图,将句子中的词语作为图的顶点,并通过词向量表示这些顶点的特征。图的边则代表词语之间的句法依赖关系。该方法不仅考虑了句子结构的信息,还通过注意力机制增强了模型的性能和准确性。
具体步骤如下:
(1)通过Bi-LSTM隐藏层,获取每个词的初步特征表示,然后通过权重矩阵进行线性变换,得到增强特征。
(2)对于每个词,计算它与其他词之间的影响程度。
(3)使用激活函数对每对词的增强特征进行非线性变换,得到每对词之间的注意力值。
(4)对每个词,计算它与所有相连词之间的加权求和系数。
(5)通过标准化处理,得到每个词与其相连词之间的最终注意力系数。
(6)计算每个词的最终特征表示。输出每个词的最终特征向量。
结合传统的句法依赖树模型,并将其升级为句法依赖图。应用GAT和Bi-LSTM模型,并将LSTM层、线性层和GAT层放入序列到序列(seq2seq)框架中进行堆叠,以实现对LNG终端风险因素的因果提取。步骤如下图所示。
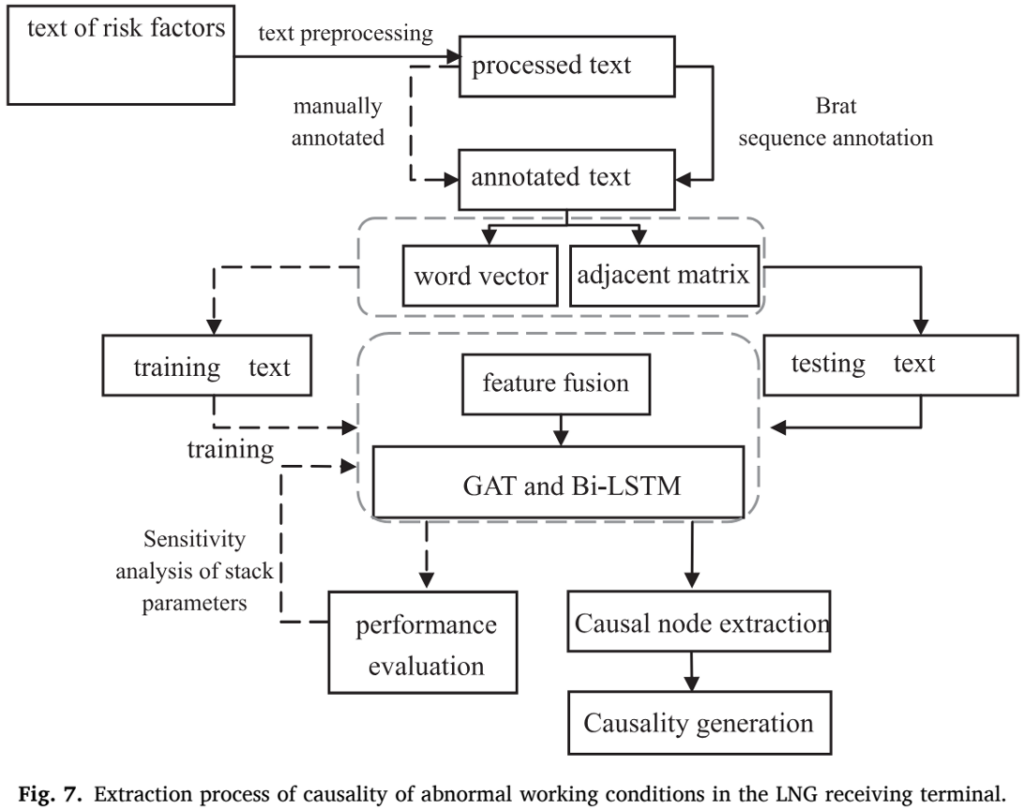
实验结果
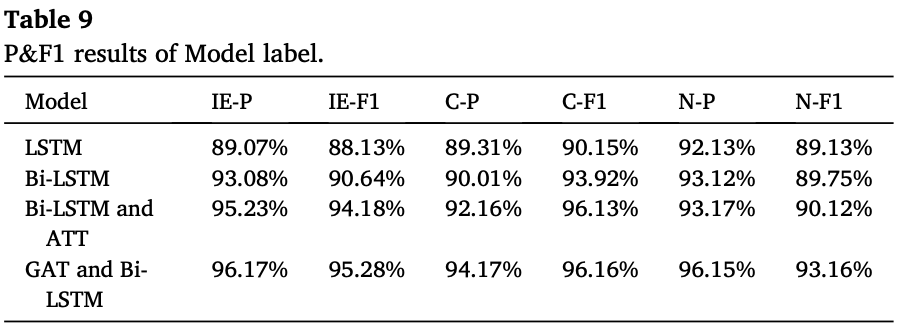
使用句法依赖图和词向量结合的GAT和Bi-LSTM模型在因果标签识别中展现了优势。“IE”和“C”的准确率分别提高了7.1%和4.86%,F1分数分别提高了6.51%和7.01%,相比其他三种传统方法有显著提升。
GAT和Bi-LSTM模型在因果信息的细粒度上表现优于其他模型,达到了最高准确率92.17%。表中的一因一果准确率高于多因多果的准确率。
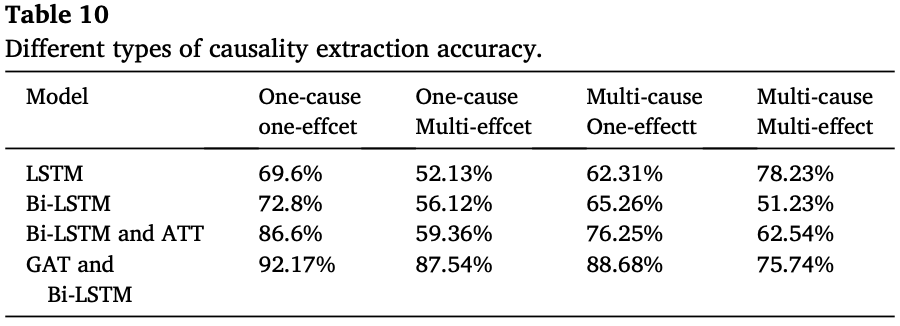
这种现象的潜在原因如下:
(1)标签识别的实体定义模糊,包含多因多果的句子的语义更加复杂。
(2)存在大量的因果实体,很难在单个句子中同时提取所有这些实体。
在相同数量的隐藏层下,GAT和Bi-LSTM模型在训练过程中收敛速度略慢于其他模型,但训练集的损失较少。
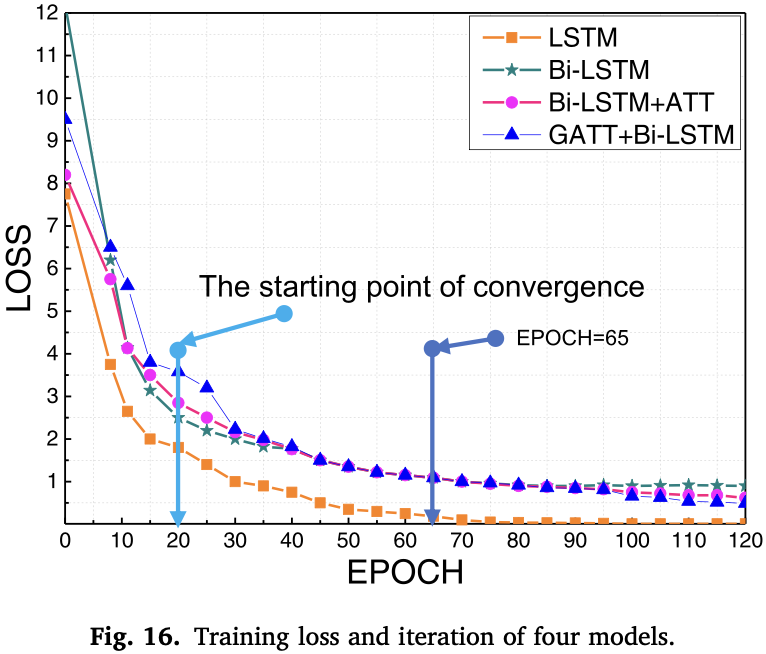
GAT和Bi-LSTM模型在初始训练阶段验证集准确率上升缓慢,在约20次迭代后快速增加,65次迭代后趋于平稳,并在120次迭代时达到最大值。
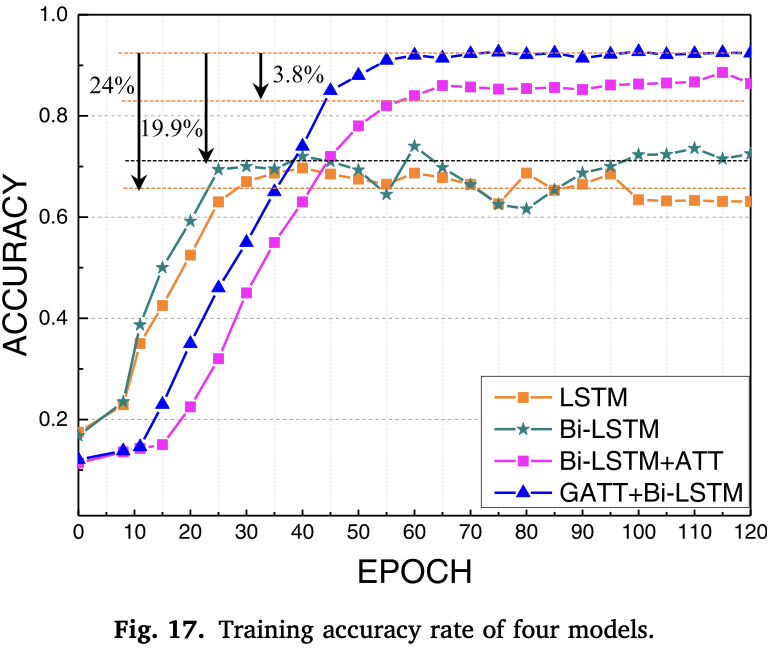
与LSTM、Bi-LSTM和Bi-LSTM和ATT模型相比,GAT和Bi-LSTM模型在平均训练性能上分别提高了24%、19.9%和3.8%。这表明,集成算法相较于单一算法具有更优的平滑性和准确性,图信息嵌入增强了模型对原始线性特征的学习性能,注意力机制对因果提取训练有利。
总结
本研究针对LNG卸载系统异常因果关系提取,开发了GAT和Bi-LSTM的建模框架。此外,提出了一种有效的方法,将词向量线性数据和语法依存图数据融合,以提高GAT和Bi-LSTM的性能。
该方法设置了两个特征通道:一个是文本词向量特征通道,另一个是有向邻接矩阵特征增强通道。文本词向量通道基于开源的文本词向量训练模型生成,词向量可以准确高效地提取因果语言。有向邻接矩阵是从因果语料库的语法依存关系中获得的,代表了因果节点的方向性和因果表达的依存关系。
提出的GAT和Bi-LSTM模型框架在特征工程中创新性地表达了图和线性特征,与传统的词向量特征相比,在因果关系提取方面表现更好。