作者:Akihito Nishikawa, Yuiko Sakuma, Yuma Okuda, Hiroaki Nishi,
来源:IEEJ Trans 2024
一、研究背景与意义
训练机器学习 (ML) 模型时,通常将所有数据集中在训练模型的主机上。然而,集中式方法在处理受隐私或监管限制的数据集时面临挑战,从而限制了数据的共享、使用和传输。
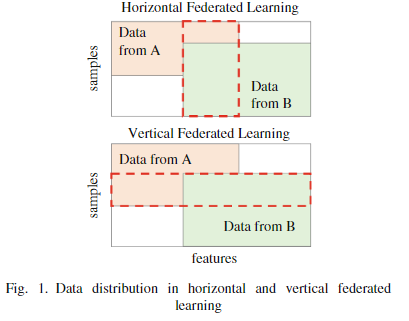
为了解决数据无法聚合到中央服务器的问题,联邦学习(FL)作为一种有前途的分布式机器学习范式应运而生。FL 包含由数据分布特征定义的两个主要类别:水平 FL (HFL) 和垂直 FL (VFL)。 HFL涉及基于样本空间来划分数据集,而VFL涉及基于特征空间来划分数据集。在多个服务协作为使用多个服务的特定用户生成推理的场景中,VFL 特别有价值。
通过使客户能够利用他们无法直接访问的功能,VFL 有可能提高推理的准确性。传统的 VFL 方法利用客户之间的协作来推断所有客户共享的共同全球目标。然而,在许多现实情况下,每个客户都有一个独特的任务,可以使用自己的数据集来完成。
关于VFL我们可以考虑这样一个场景:患者咨询多个医疗机构,每个医疗机构专门负责不同的科室。因此,每个机构都会对患者进行不同的测试并保留各自的结果。因此,每个医疗机构都会开发自己的机器学习模型,利用获取的数据来推断患者。在这种情况下,每个客户(医疗机构)共享一个共同的样本空间(患者),但拥有唯一的特征空间(测试结果),因此数据是垂直分布的。值得注意的是,出于隐私考虑,医疗数据无法集中。另一个例子涉及多服务平台上的服务协调。在这样的平台中,用户通过统一的ID来使用各种服务。每个服务都会收集包括用户服务使用历史和属性信息在内的数据。然后利用这些数据构建旨在提高服务质量的机器学习模型。
二、相关工作
2.1 纵向联邦学习
联邦学习方法根据数据划分的形式可以分为两类——HFL和VFL,如图1所示。 VFL,也称为特征分区联邦学习,假设所有客户端都具有相似或相同样本空间的数据集,但数据集的特征空间不同。 VFL的一个典型例子是多个医疗机构合作推断患者病情[9]。 患者根据病情到不同的医疗机构就诊,每个机构对患者进行不同的检查,导致每个机构(客户端)对每个患者存储的医疗信息(特征空间)不同。 尽管医疗信息对隐私敏感并且必须保密,但如果使用从多个医疗机构之间协作获得的特征构建机器学习模型,而不是仅仅使用从多个医疗机构获得的特征,那么预计可以提高个体患者的推理性能。 单一医疗机构。 在 FedAvg 等 HFL 方法中,预计会有大量客户端参与联邦学习过程,而在 VFL 方法中,客户端数量预计不会很大,因为多个客户端可能通过共享各自的特征来相互合作 。
2.2 个性化联邦学习
由于客户之间的异质性,联邦学习面临着一些挑战。 数据异构性是指每个客户端持有的数据的非独立同分布。 使用 FedAvg 在非 IID 数据上获得的全局模型的准确性不足。 此外,计算资源、任务和模型结构可能因客户端而异,进一步加剧了异构性问题。 为了应对这一挑战,个性化联邦学习(PFL)被开发为一种 FL 方法,它认识到由于这种异构性,为所有客户构建单一全局模型是不切实际的。 PFL旨在为每个客户创建单独的模型,同时仍然受益于 FL 的协作性质。
三、模型与方法
作者提出了一种称为个性化垂直联合学习(pvFed)的 VFL 方法,该方法可以解决每个客户的单独任务。 如图 2 所示。
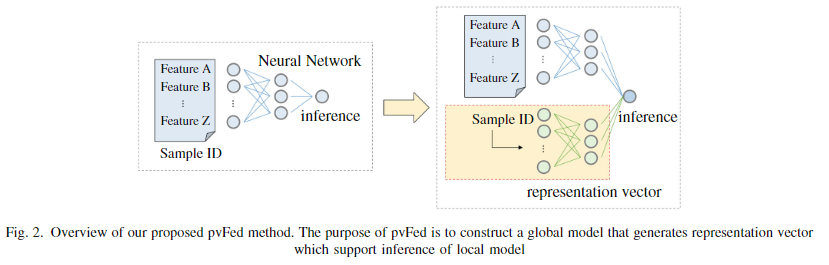
pvFed 的主要目标是构建一个全局模型,该模型生成辅助表示向量,以在客户使用单个模型时帮助推理。 在pvFed中,全局模型使用公共样本ID作为输入来生成表示向量。 传统上,当客户具有不同的任务和特征空间时,每个客户只能使用自己的数据来训练模型。 相比之下,pvFed 使客户能够在推理过程中利用共享样本中的信息。
为了确保隐私,pvFed仅从客户端到服务器共享其本地编码器,从而保护原始数据。 通信仅发生在服务器和客户端之间,消除了客户端之间的 P2P 通信的需要。
图 3 说明了 pvFed 的训练过程,它集成了三个不同的神经网络 (NN):特定于客户端的本地模型、本地编码器和全局编码器。 每个本地模型都是根据各自客户的独特任务量身定制的,包括定制的架构和损失函数。 本地和全局编码器的任务是从样本 ID 生成表示向量。 局部模型训练后,局部编码器使用蒸馏技术进行训练,以模仿这些模型的特征提取层的输出。 经过训练的本地编码器随后被传输到服务器以进行全局编码器的训练。 与局部编码器类似,全局编码器处理样本 ID 以生成表示向量。 全局编码器的训练数据是通过连接和降维局部编码器生成的向量来获得的。
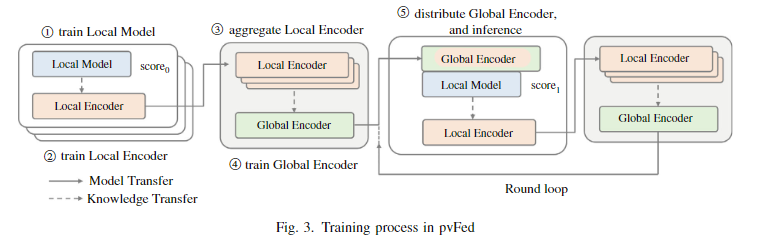
训练好的全局编码器分发给客户端并用于局部模型的推理。 然后,再次训练本地编码器。 这就是 pvFed 中的一轮,重复这些轮,直到客户端任务的推理精度收敛。 图 4 显示了 pvFed 单次迭代的伪代码。 在全局编码器的训练循环之前,每个客户端使用其单独的本地数据集独立训练其自己的本地模型和编码器。 本地编码器的训练是通过本地模型逻辑的蒸馏来实现的。 采用的损失函数是欧几里德距离,常用于对比学习 ,这是一种训练 DNN 模型的方法,如果模型的输入相似,它们的中间表示也将相似。

训练后的本地编码器被传输到服务器并用于训练全局编码器。 训练全局编码器的目的是模仿通过使用样本 ID 作为输入聚合本地编码器的输出而获得的向量。 作者主要采用了三种基于降维的聚合方法:均值聚合、自动编码器(AE)聚合和主成分分析(PCA)聚合。
来自服务器的经过训练的全局编码器被分发到客户端并用于本地模型的重新训练和推理过程。 在此设置中,局部模型的输出层通过合并全局编码器和局部模型的特征提取器的输出来生成预测。 由于输入大小的改变,这种差异需要重新定义输出层,这与仅使用本地模型进行训练时不同。 因此,该输出层被重新定义和重新训练。 然而,特征提取器组件保持不变,以保持一致性并防止潜在空间的多样化,这可能是由于模型初始参数值的改变而导致的。
pvFed 中的每一轮都包含从本地编码器聚合到客户端重新训练的过程。 全局编码器通过迭代轮次进行训练。
四、实验与分析
4.1 数据集设置
作者采用了两种不同类型的数据:图像和表格数据集。图像数据集 FEMNIST包含 805 263 个手写字母数字图像。每个图像都与 62 个字母数字标签和 3550 个作者标签之一相关联。表格数据集是信用卡欺诈检测 (CCFD) 数据集,包括 2013 年 9 月欧洲持卡人的 284 807 笔信用卡交易,由 Worldline 和 ULB(布鲁塞尔自由大学)机器学习小组提供。 CCFD 数据集包含每笔交易的 28 个数字属性,以及指示其欺诈状态的标签。
FEMNIST 数据集按字母数字标签划分并随机分配给 10 个客户端。因此,每个客户都会收到来自所有作家的一组 6 或 7 个不同的字母数字图像。每个客户的任务是将分配的图像分类到各自的字母数字标签中。每个客户端都有不同类型的图像供作者使用,因此数据集的划分是垂直的[30],并且客户端的任务在对不同类型的图像进行分类方面有所不同。
CCFD 数据集的 28 个特征随机分配给四个客户端。 每个客户的任务都是进行回归分析,利用他们拥有的七个特征中的六个作为解释变量来预测第七个特征。 值得注意的是,本实验没有使用 CCFD 数据集中的交易欺诈标签。 由于每个客户端具有不同的特征,因此数据划分是垂直的。 由于他们处理的目标变量不同,分配给每个客户的任务也不同。
4.2 结果简析
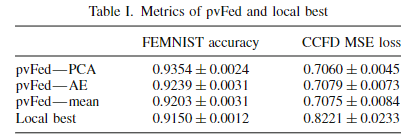
表 I 列出了使用三种聚合方法的 pvFed 指标。 为了进行比较分析,还提供了每个客户仅使用自己的数据独立训练本地模型(称为本地最佳)的场景的指标。 pvFed 在所有实验中的准确性均超过了局部最佳结果。 在评估的聚合方法中,PCA 聚合的准确性最高。 这在 FEMNIST 数据集中尤其明显,与其他方法相比,基于 PCA 的降维对于训练 pvFed 的全局编码器更有效。 PCA 聚合的准确率达到了 0.9354,而 Local Best 的准确率为 0.9150,将本地模型的推理失败率降低了 24%。
五、总结
本文提出的pvFed 的主要目标是构建一个能够生成表示向量的全局模型,以促进每个客户端的推理。 为了实现这一目标,pvFed 除了每个客户端用于其特定任务的本地模型和 pvFed 的目标全局编码器之外,还采用了第三种模型,即本地编码器。 利用蒸馏和降维,本地编码器将知识从客户特定的本地模型传输到全局编码器。
由于只有本地编码器从客户端共享到服务器,因此客户端保存的原始数据是保密的。 全局编码器输出的向量对于样本来说是独特的,并且被设计为独立于任何客户端的特定任务,从而使其能够普遍适用于所有客户端。
通过在垂直数据分区下对两种不同的数据类型(图像和表格数据集)的研究与分析, 证明了 pvFed 中全局模型生成的表示向量对于客户端推理的有效性。 此外,pvFed 证明了客户推断的准确性更高,即使在某些客户关于推断样本的数据不足的情况下也是如此。