作者:Chaofan Li,MingHao Qin, Shitao Xiao, Jianlyu Chen, Kun Luo, Yingxia Shao,Defu Lian, Zheng Liu
单位:北京智源研究院
来源:arxiv
一、主要内容
该论文的核心贡献是提出了一种基于LLM上下文学习能力的嵌入生成方法,称为bge-en-icl。该模型通过在查询端引入少量的任务示例,显著提高了各种任务的嵌入质量。研究表明,LLMs在未修改架构的情况下,通过上下文学习能够生成高质量的嵌入。实验结果显示,该模型在MTEB和AIR-Bench基准测试上达到了新的最先进水平(SOTA)。
二、相关工作
文本嵌入在自然语言处理任务中至关重要,常用于信息检索、文本分类、推荐系统等应用。以往的工作通常基于预训练的双向编码器模型(如BERT、T5、RoBERTa),而近年来的研究更倾向于基于解码器的架构。尽管这些嵌入模型在已知领域的任务上表现优异,但它们在处理未见过的任务指令时,存在一定的局限性。因此,本文利用LLMs的上下文学习能力来增强嵌入生成模型,使其能够更好地应对未见过的任务和复杂的检索任务。
三、方法
论文中提出的bge-en-icl模型通过将少量的任务相关示例直接集成到查询提示中,从而利用上下文学习生成更高效的嵌入。该方法无需复杂的模型架构修改,仅通过在查询端添加示例,就能够提升嵌入模型在不同任务中的表现。模型的训练使用了标准的InfoNCE损失函数,并引入了批内负例和困难负例来提高训练效果。此外,模型采用了未修改的单向注意力机制,以保持其生成属性并在上下文学习中最大化其潜在能力。
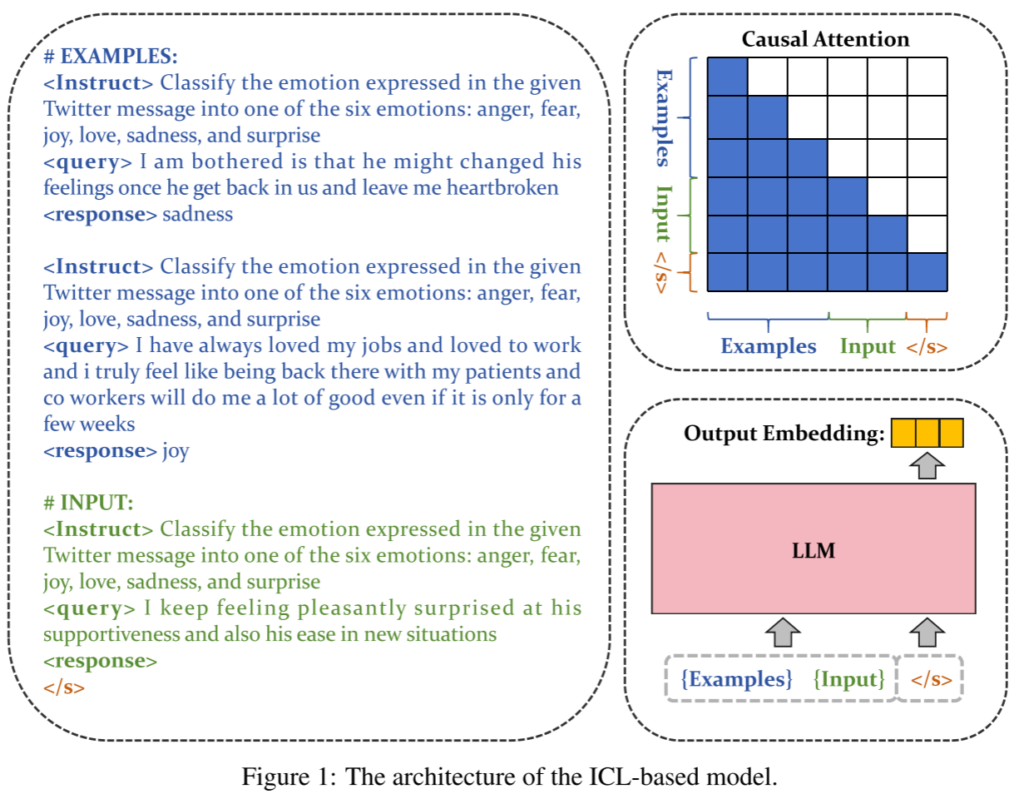
四、实验
论文的实验部分重点探讨了以下研究问题:
- 上下文学习策略在零样本和少样本学习场景中的有效性。
- 上下文学习策略与传统训练方法相比的性能差异。
- 批内示例的引入对上下文学习策略性能的影响。 实验结果表明,在MTEB基准测试中,bge-en-icl模型在零样本和少样本场景中均表现出色,特别是在少样本学习中模型表现得更加优异。此外,实验还探讨了不同的注意力机制和池化方法,发现保持单向注意力机制和最后一个标记的池化方法效果最佳。
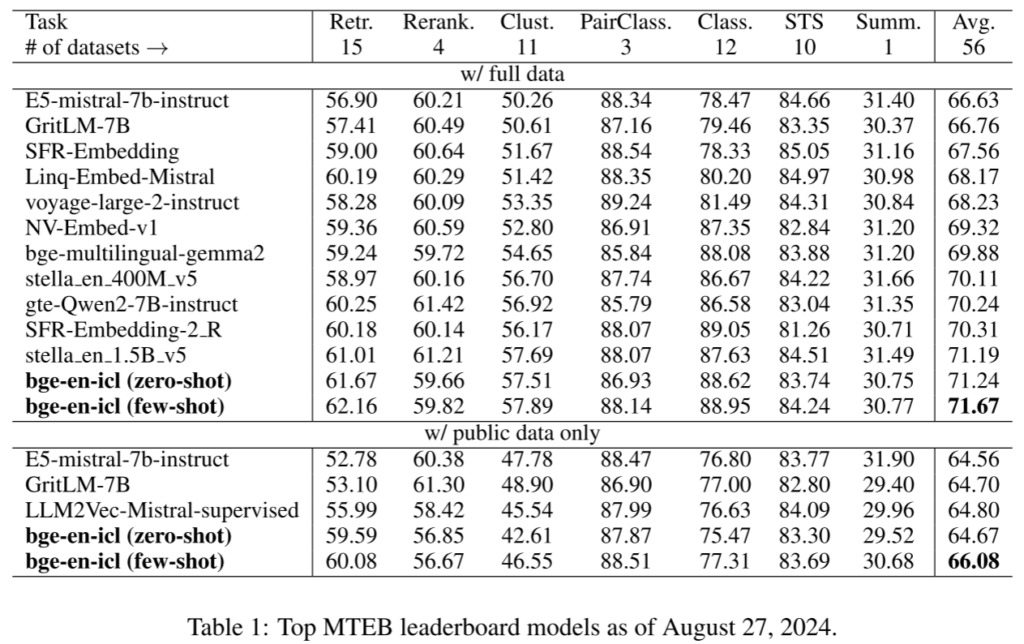
五、总结
该论文展示了通过上下文学习(ICL)增强LLMs作为嵌入模型的潜力,并证明了保持模型原始架构的简单策略在嵌入生成任务中非常有效。实验表明,bge-en-icl在多个基准测试上达到了最先进的表现,尤其是在少样本学习场景中表现出色。